Data Requirements¶
To run a session, the data must be prepared according to the following standards:
The data configuration dictated in the Session configuration
The data requirements given below for running a modelling pipeline with integrate.ai
integrate.ai supports
Private Record Linkage (PRL)
Discover the overlapping population between your data and your partner’s data without exposing individual records
Exploratory Data Analysis (EDA)
Generate summary statistics on a dataset to learn about the properties and distributions of the dataset being evaluated
Horizontal federated learning (HFL)
Train models across different siloed datasets that hold different samples over the same set of features, without transferring data between each silo
Vertical federated learning (VFL)
Train models across different siloed datasets that hold different features belonging to the same set of samples, without transferring data between each silo
Data format requirements¶
Data should be in Apache Parquet format (preferred) or
.csv, and can be hosted locally, in an S3 bucket or in an Azure blob. Note:.csvis only recommended for small data files less than 1GB.Proper row groups must be used when exporting the data to parquet files. Depending on the tool used to write the parquet file, you can do so by specifying the
row_group_sizeas the number of records per group, or set theblock_sizeas the physical storage size per group (recommended value is 100MB).a. The recommended value for row_group_size is 500k records. Large datasets are processed by moderate-sized partitions (row groups) by default. These partitions should be large enough that each of them contains sufficient information about the whole data. However, it should not be too large, so that they can be processed efficiently with regard to memory and computation usage.
The matching columns (that is, the columns used in the matching algorithm between datasets for PRL) are defined (that is, you must specify which columns should be used for the match). For information about handling duplicated values of these matching columns, see the section Configure PRL session.
For HFL (different samples, same features) - Column names must be consistent across datasets. All column names (predictors and targets) must contain only alphanumeric characters (letters, numbers, dash -, underscore _) and start with a letter. You can select which columns you want to use in a specific training session.
When working with a train set and a test set of data, each dataset must be registered separately. That is, you must register both your training dataset and your test dataset.
Dataset Validation¶
To ensure your dataset meets the data format requirements, run a validation session after you register your dataset. Validation is the process of running an individual EDA session on the registered dataset to determine whether or not the data is formatted correctly for use in the integrate.ai platform.
You can only validate datasets that you have registered. Datasets owned by other users do not have a Validate button.
To validate a dataset:
On the Datasets page in your workspace UI, locate and select the dataset card.
Click Validate data.
The session runs on all columns in the dataset.
You can return to the Datasets page and continue working while the validation session runs. The status message on the dataset card updates to reflect the session status.
Note: Depending on the size of the dataset and the number of columns included, this session may take some time to complete. To reduce the number of columns, use a data schema as described below.
Validate against a data schema¶
Validating against a data schema allows you to have more fine-grained control over the columns that are validated. This is an optional step but can be useful to reduce the number of columns and therefore the runtime of the session.
The schema must be a CSV or JSON file with the following column headers:
column_name- standard column/feature namefriendly_name- human-readable namedescription- describe what the feature representsis_categorical(true/false) - specify if the feature is categoricalexclude(true/false) - specify if the column should be excluded from EDA.
Prepare this file before you run the validation.
To validate against a data schema:
On the Datasets page in your workspace UI, locate and click the dataset card.
Select the Dataset schema tab.
Upload a data schema, formatted as instructed, to the dataset.
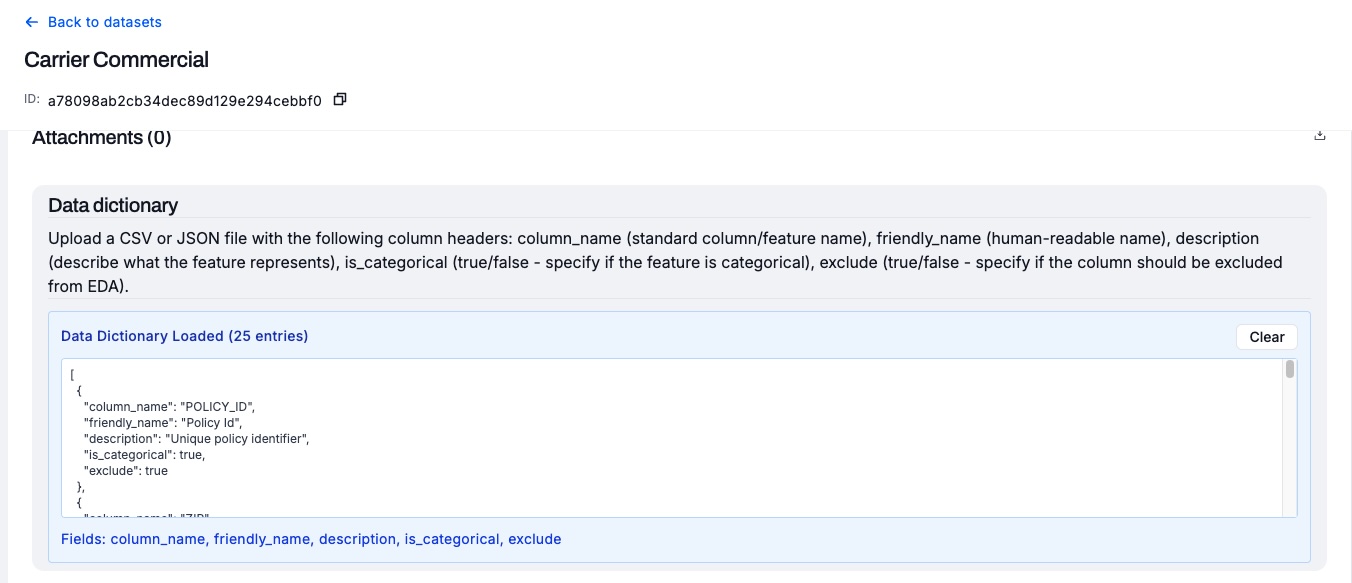
Click Validate data. The session runs and validates the data against the provided schema.
Reviewing validation results¶
If the dataset is deemed Invalid:
Open the dataset details for the invalid dataset.
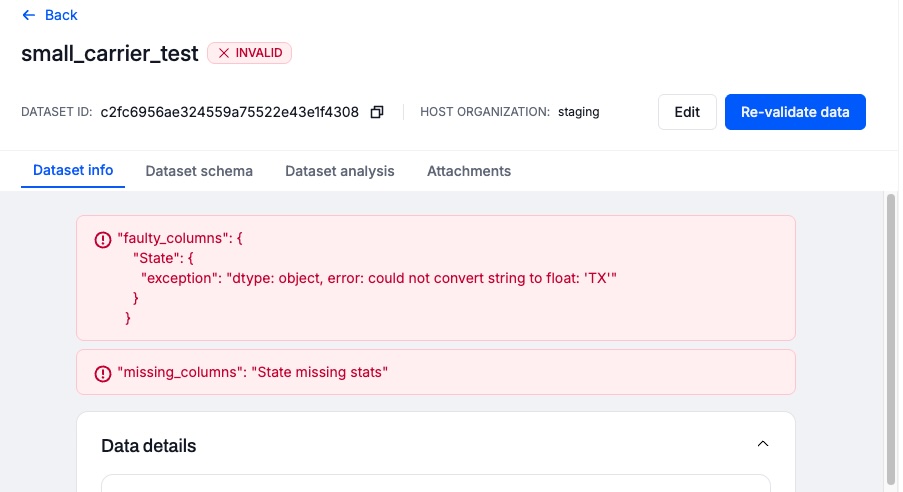
The error indicates that the State column has the wrong Type.
Click Dataset schema.
Locate the
Statecolumn and enable theCategoricaltoggle.Click Save changes.
Click Re-validate data.
Note
In this example, the session completed successfully and there was an error in the validation against the dataset schema. The dataset is valid and can be used for sessions, however the results may not be correct because the type of one column is incorrect.
Reviewing logs
When a dataset validation session fails, you can review the logs for the session to determine the error.
To review the logs:
Open the Sessions page.
From the Session type filter, select Exploratory data analysis (EDA).
From the Status filter, select Failed.
Locate the validation session in the list. For example:

Click the session.
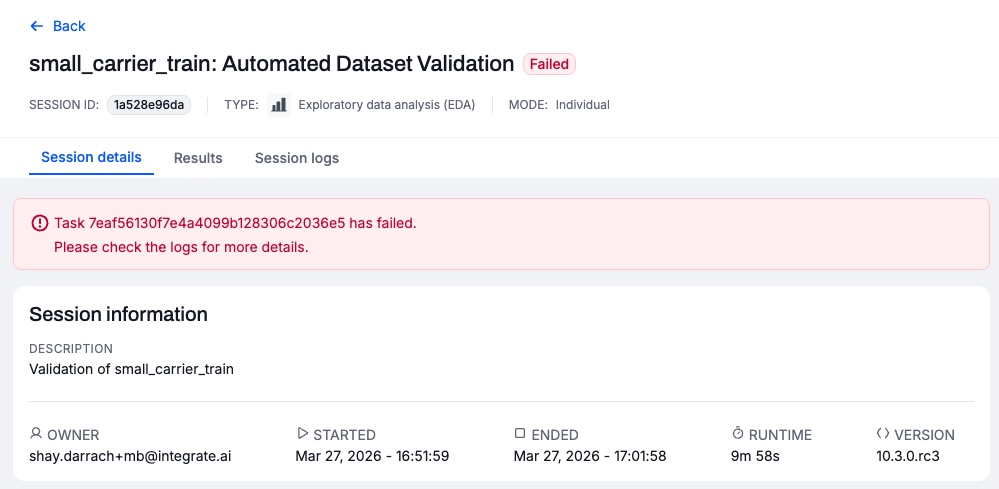
Click the Session logs tab. Select the client EDA and review the logs for errors.
Correct the issues in your dataset, update the dataset registration, and run validation again.
Simple Data Harmonization¶
Harmonization ensures that your data is formatted correctly to be used in a session with a partner’s data. In this scenario, the partner connects their dataset, with an attached schema, to your workspace. You then use their schema to validate your data.
To perform simple harmonization:
Open the dataset card for your partner’s dataset. This will be indicated by a “Partner Dataset” label on the dataset card.
Select the Dataset schema tab.
On the top right corner of the schema table, click the download icon.
Go back to the Datasets page. Select the dataset you want to use with the partner’s data.
Open the dataset and select the Dataset schema tab.
Upload the dataset schema you downloaded from the partner dataset.
Click Validate data. Wait for the process to complete.
If necessary, review the results and correct any issues.
You can also use a data dictionary from a partner to ensure that your data will work well in a session with the partner data.
Feature Engineering Requirements¶
In order for data to be used to run predictive modelling sessions in the platform (ie GLMs, GBMs, NNs etc), it must be fully feature engineered. Note that the registered datasets must always include the original columns with the original name, as well as the feature engineered columns.
The requirements for the processed columns that will be used as input for modelling pipelines are as follows:
Create one file that includes both raw and pre-processed columns.
All processed columns must be numerical, with the exception of ID columns used for PRL.
Processed columns must not contain NULL values; meaning that missing values are imputed.
Each row must correspond to one observation.
For processed columns that are continuous variables, they must be standardized to have
mean = 0andstd = 1. This requirement is highly recommended for GLM and NN, but is not required for GBM.For categorical variables, features must be encoded (e.g., by one-hot-encoding). For example, if there is a column
marital_status, and the values aremarriedanddivorced, there should be three columns in the dataset: the original columnmarital_status,marital_status_married, andmarital_status_divorced.Feature engineering must be consistent across the data products. For example, if the datasets contain categorical values, such as
country, these values must be encoded the same way across all the datasets. For thecountryexample, this means that the samecountryvalue translates to the same numerical values across all datasets that will participate in the training.
Use the Transform session to preprocess your data as necessary.
Caution
If the above criteria are not met, the training will fail to run.