VFL SplitNN Model Training¶
VFL Training Session Example¶
To create a VFL train session, specify the prl_session_id indicating the PRL session that you created to link the datasets together. The vfl_mode needs to be set to train.
This model supports learning rate schedulers.
Ensure that you have run a PRL session to obtain the aligned dataset. The PRL session ID is required for the VFL training session.
Create a
model_configand adata_configfor the VFL session.
model_config = {
"strategy": {"name": "SplitNN", "params": {}},
"model": {
"feature_models": {
"passive_client": {"params": {"input_size": 7, "hidden_layer_sizes": [6], "output_size": 5}},
"active_client": {"params": {"input_size": 8, "hidden_layer_sizes": [6], "output_size": 5}},
},
"label_model": {"params": {"hidden_layer_sizes": [5], "output_size": 2}},
},
"ml_task": {
"type": "classification",
"loss_function": "logistic",
"params": {
"loss_weights": None,
},
"init_params": {active_name: baseline_init},
"optimizer": {"name": "SGD", "params": {"learning_rate": 0.2, "momentum": 0.0}},
"seed": 23, # for reproducibility
}
data_config = {
"passive_client": {
"label_client": False,
"predictors": ["x1", "x3", "x5", "x7", "x9", "x11", "x13"],
"target": None,
},
"active_client": {
"label_client": True,
"predictors": ["x0", "x2", "x4", "x6", "x8", "x10", "x12", "x14"],
"target": "y",
},
}
Parameters:
strategy: Specify the name and parameters. For VFL, the strategy is SplitNN.model: Specify thefeature_modelsandlabel_model.feature_modelsrefers to the part of the model that transforms the raw input features into intermediate encoded columns (usually hosted by both parties).label_modelrefers to the part of the model that connects the intermediate encoded columns to the target variable (usually hosted by the active party).
ml_tasktype- You can chose betweenclassificationorregression.loss_function- You can choose from the following list:logistic,mse,poisson,gamma,inverseGaussianandtweedie. Note:tweediehas an additionalpowerparameter to control the underlying target distribution.
init_params: Specify a dictionary forbaseline_initwith the following structure:
{'layer.weight': [[0.325680,
0.4532324,
-0.025357,
-1.066511,
... ]],
'layer.bias': [0.0462449]}
},
Alternately, you can retrieve the baseline_init directly from the baseline training as follows:
baseline_init = <hfl_session>.model().as_serializable()
where <hfl_session> is an example session name.
optimizer- The optimizer to use for the training process. We support all the PyTorch optimizers listed here, except for theLBFGS. Setnameas the corresponding optimizer name (e.g.SGD,Adam). Extra parameters for the optimizer can be specified under the fieldparams.seed: Specify a number.
Create and start a VFL training session¶
Specify the PRL session ID of a succssful PRL session that used the same active and passive client names.
Ensure that the vfl_mode is set to train.
vfl_train_session = client.create_vfl_session(
name="Testing notebook - VFL Train",
description="I am testing VFL Train session creation with a task runner through a notebook",
prl_session_id=prl_session.id,
vfl_mode='train',
min_num_clients=2,
num_rounds=2,
package_name="iai_ffnet",
data_config=data_config,
model_config=model_config
).start()
vfl_train_session.id
Set up the task builder and task group for VFL training¶
Create a task in the task group for each client. The number of client tasks in the task group must match the number of clients specified in the data_config used to create the session.
vfl_task_group_context = (SessionTaskGroup(vfl_train_session)\
.add_task(iai_tb_aws.vfl_train(train_dataset_name="active_train", test_dataset_name="active_test",
batch_size=16384 * 32,
eval_batch_size=5000000,
job_timeout_seconds=28800,
client_name="active_client"))\
.add_task(iai_tb_aws.vfl_train(train_dataset_name="passive_train", test_dataset_name="passive_test",
batch_size=16384 * 32,
eval_batch_size=5000000,
job_timeout_seconds=28800,
client_name="passive_client"))\
.start())
The following parameters are required for each client task:
train_dataset_nametest_dataset_namebatch_size: specify a value for batching the train dataset during training. The default value of 1024 is meant for use only with small datasets (~100MB).eval_batch_size: specify a value for batching the test dataset during training with large datasets.job_timeout_seconds: specify a value that corresponds to the amount of time the training session is estimated to take. For large datasets, the default value of7200must be increased.client_name: must match the client_name specified in the PRL session used to determine the overlap
Sessions may take some time to run depending on the compute environment. You can check the session status in the workspace, on the Sessions page. Wait for the status update to Completed.
View the training metrics¶
Once the session completes successfully, you can view the training metrics.
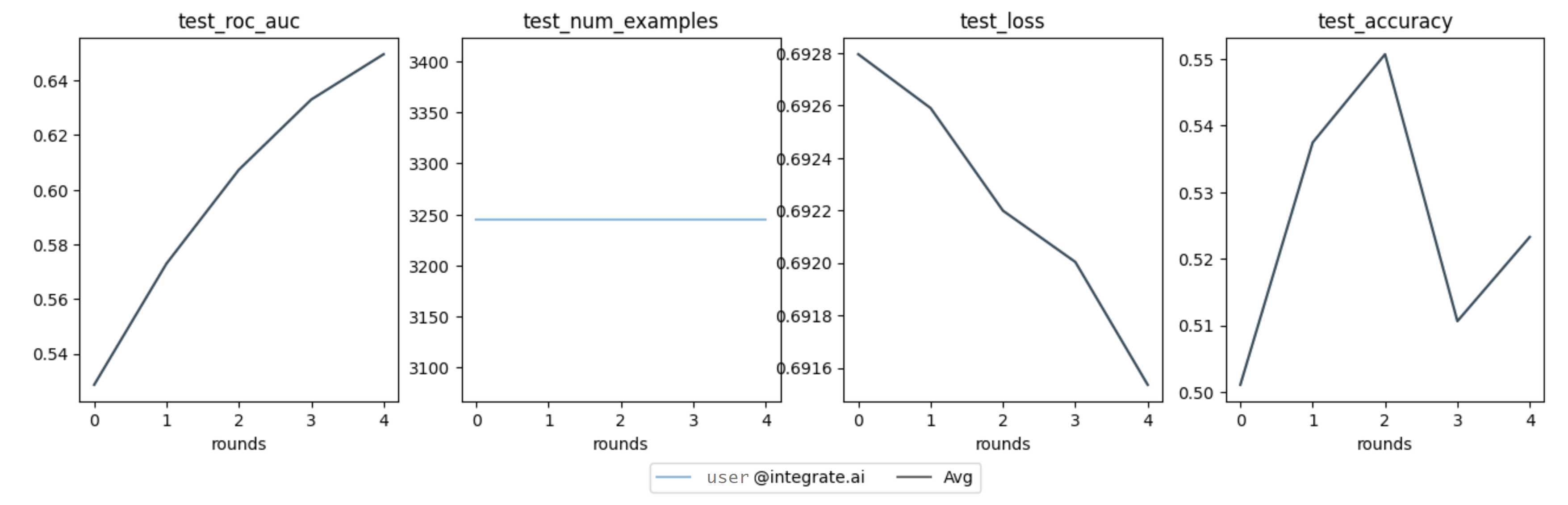
metrics = vfl_train_session.metrics().as_dict() metrics
# Example results
{'session_id': '498beb7e6a',
'federated_metrics': [{'loss': 0.6927943530912943},
{'loss': 0.6925891094472265},
{'loss': 0.6921983339753467},
{'loss': 0.6920029462394067},
{'loss': 0.6915351291650617}],
'client_metrics': [{'user@integrate.ai:79704ac8c1a7416aa381288cbab16e6a': {'test_roc_auc': 0.5286237121001411,
'test_num_examples': 3245,
'test_loss': 0.6927943530912943,
'test_accuracy': 0.5010785824345146}},
{'user@integrate.ai:79704ac8c1a7416aa381288cbab16e6a': {'test_num_examples': 3245,
'test_accuracy': 0.537442218798151,
'test_roc_auc': 0.5730010669487545,
'test_loss': 0.6925891094472265}},
{'user@integrate.ai:79704ac8c1a7416aa381288cbab16e6a': {'test_accuracy': 0.550693374422188,
'test_roc_auc': 0.6073282812853845,
'test_loss': 0.6921983339753467,
'test_num_examples': 3245}},
{'user@integrate.ai:79704ac8c1a7416aa381288cbab16e6a': {'test_loss': 0.6920029462394067,
'test_roc_auc': 0.6330078151716465,
'test_accuracy': 0.5106317411402157,
'test_num_examples': 3245}},
{'user@integrate.ai:79704ac8c1a7416aa381288cbab16e6a': {'test_roc_auc': 0.6495852274713467,
'test_loss': 0.6915351291650617,
'test_accuracy': 0.5232665639445301,
'test_num_examples': 3245}}]}
Plot the VFL training metrics.¶
fig = vfl_train_session.metrics().plot()
Example of plotted training metrics
Back to VFL Model Training overview.